Investigating Slow S3 Uploads from AWS EKS Pods
The Problem
At my current workplace, we have been using AWS EKS unmanaged clusters. Recently, our engineering teams have noticed an alarming issue with unreasonably slow S3 file uploads from their applications.
To investigate further, they conducted a comparison by running the same application on their local computers. Surprisingly, they observed that uploading a 10KB file to S3 took approximately 5 seconds on our EKS cluster. However, on their local machines, the identical upload process took approximately 1 second. Consistent testing revealed an average slowness factor of 5 when compared to the local computer uploads.
This noticeable increase in latency raised significant concerns, urging us to uncover the underlying root cause to identify possible solutions.
Investigation
To identify the issue and locate the bottleneck, we came up with the following plan:
-
Create a S3 bucket in the region where our EKS cluster is running.
-
Deploy a debug pod in the EKS cluster using the latest AWS CLI docker image.
# Debug pod configurations
apiVersion: apps/v1
kind: Deployment
metadata:
name: debug
spec:
selector:
matchLabels:
app: debug
replicas: 1
template:
metadata:
labels:
app: debug
spec:
containers:
- name: debug
image: amazon/aws-cli
command: ["sleep", "infinity"]
- Locate the EKS node where the debug pod is running.
kubectl get pods -l=app=debug -o wide
- Create a 10KB file and upload it to the S3 bucket using AWS CLI from both the debug pod and EKS node where the debug pod is deployed. Measure the time taken for each upload.
# AWS CLI upload command
time aws s3 --debug cp 10kb.png s3://yasithab-debug-bucket/10kb.png
Identifying the Issue
Based on the test conducted, it was discovered that uploading the 10KB file from the EKS node takes around 1 second, which is similar to uploads from a local computer. However, uploading the same file from the pod running on the same EKS node takes approximately 5 seconds. This indicates that there is something in between causing this issue, but the exact cause is still unknown.
# AWS CLI upload results from the EKS node where the debug pod is running
real 0m1.460s
user 0m0.908s
sys 0m0.085s
# AWS CLI upload results from the debug pod
real 0m5.612s
user 0m0.956s
sys 0m0.073s
As we have AWS enterprise support, we reached out to them with the test results and debug logs. They recommended provisioning a new EKS cluster and conducting the same test to isolate any other dependencies. However, we decided against this approach as we consider it unnecessary to set up a new cluster solely for debugging this issue. Therefore, we are currently on our own in resolving this matter, unfortunately.
With no clear direction at this stage, a possible course of action is to compare the AWS CLI debug logs for both node and pod uploads. This can be achieved by utilizing a file comparison tool. Initially, the focus was on investigating potential network delays by comparing the duration of the upload process.
The upload process began when the CLI displayed the following lines.
MainThread - botocore.endpoint - DEBUG - Setting s3 timeout as (60, 60)
MainThread - botocore.utils - DEBUG - Registering S3 region redirector handler
The upload process ended when the CLI displayed the following lines.
upload: ./10kb.png to s3://yasithab-debug-bucket/10kb.png
Thread-1 - awscli.customizations.s3.results - DEBUG - Shutdown request received in result processing thread, shutting down result thread.
Then, the duration from the beginning of the upload to the end of the upload event was calculated.
-
In the node upload process, the start time was recorded as 2023-07-13 11:03:14,047, and the end time was recorded as 2023-07-13 11:03:14,161. Hence, the upload process took 114 milliseconds.
-
In the pod upload process, the start time was recorded as 2023-07-13 10:57:54,740, and the end time was recorded as 2023-07-13 10:57:54,828. Hence, the upload process took 88 milliseconds.
The almost identical upload times indicate that this issue is not caused by network latency.
Upon reviewing the logs further, it was observed that in the pod upload debug log, most of the time was spent on establishing the connection to the Instance Metadata Service (IMDS) endpoint. This process took around 1 second and was attempted three times, totaling approximately 4 seconds. On the other hand, the initialization of the connection to the IMDS endpoint from the EKS node where the debug pod is deployed, only took 190 milliseconds.
# From the EKS node where the debug pod is deployed - 190 milliseconds
2023-07-13 11:03:13,857 - MainThread - botocore.utils - DEBUG - IMDS ENDPOINT: http://169.254.169.254/
2023-07-13 11:03:14,047 - MainThread - botocore.endpoint - DEBUG - Setting s3 timeout as (60, 60)
# From the debug pod - 4 seconds and 259 milliseconds
2023-07-13 10:57:50,481 - MainThread - botocore.utils - DEBUG - IMDS ENDPOINT: http://169.254.169.254/
2023-07-13 10:57:54,740 - MainThread - botocore.endpoint - DEBUG - Setting s3 timeout as (60, 60)
When comparing the total time taken from the debug pod (5 seconds and 612 milliseconds) with the time taken for establishing the connection to the Instance Metadata Service (IMDS) endpoint from the debug pod (4 seconds and 259 milliseconds), a difference of 1 second and 353 milliseconds is observed. Remarkably, this difference closely matches the time taken from the EKS node upload results.
Hooray! The Instance Metadata Service (IMDS) has been identified as the bottleneck. However, the next step is to understand why this is happening and determine how to resolve it.
What is IMDS and What it does here?
The AWS Instance Metadata Service (IMDS) is a service that allows EC2 instances to access information about themselves. This information includes details like the instance ID, instance type, network configurations, identity credentials, security groups, and more. Applications running on EC2 instances can use IMDS to retrieve dynamic information about the instance. IMDS has two versions available.
- Instance Metadata Service Version 1 (IMDSv1) – a request/response method.
- Instance Metadata Service Version 2 (IMDSv2) – a session-oriented method.
By default, you have the option to use either IMDSv1 or IMDSv2, or both. The instance metadata service differentiates between IMDSv1 and IMDSv2 requests based on the presence of specific PUT or GET headers, which are exclusive to IMDSv2. If you configure IMDSv2 to be used in the MetadataOptions, IMDSv1 will no longer function.
To retrieve the MetadataOptions for an EKS node, use the following command. Replace <EKS_NODE_INSTANCE_ID> with the specific instance ID of the EKS node you wish to retrieve the MetadataOptions for.
aws ec2 describe-instances --instance-ids <EKS_NODE_INSTANCE_ID> --query "Reservations[].Instances[].MetadataOptions"
The above command will give an output similar to the following:
[
{
"State": "applied",
"HttpTokens": "optional",
"HttpPutResponseHopLimit": 1,
"HttpEndpoint": "enabled",
"HttpProtocolIpv6": "disabled",
"InstanceMetadataTags": "disabled"
}
]
In the output, it shows that the HttpTokens attribute is set to optional.
When the HttpTokens is set to optional, it sets the use of IMDSv2 to optional. You can retrieve instance metadata with or without a session token. Without a token, IMDSv1 role credentials are returned, and with a token, IMDSv2 role credentials are returned.
On the other hand, when HttpTokens is set to required, IMDSv2 becomes mandatory. You must include a session token in your instance metadata retrieval requests. In this case, only IMDSv2 credentials are available; IMDSv1 credentials cannot be accessed.
IMDSv2 is an improved version of instance metadata access that adds an extra layer of security against unauthorized access. To use IMDSv2, a PUT request is required to establish a session with the instance metadata service and obtain a token. By default, the response to PUT requests has a response hop limit of 1 at the IP protocol level.
However, this limit is not suitable for containerized applications on Kubernetes that operate in a separate network namespace from the instance. EKS managed node groups that are newly launched or updated will have a metadata token response hop limit of 2. However, in the case of self-managed nodes like ours, the default hop limit is set to 1. Therefore, setting the HttpPutResponseHopLimit to 2 in our EKS is mandatory for retrieving InstanceMetadata over IMDSv2.
How does the upload work with HttpPutResponseHopLimit set to 1 despite the slow upload speed?
When the HttpTokens attribute is set to optional, the AWS CLI/SDK automatically use IMDSv2 calls by default. If the initial IMDSv2 call does not receive a response, the CLI/SDK retries the call and, if still unsuccessful, fallback to using IMDSv1. This fallback process can introduce delays, especially in a container environment.
In a container environment, if the hop limit is set to 1, the IMDSv2 response does not return because accessing the container is considered an additional network hop. To avoid the fallback to IMDSv1 and the resulting delay, it is recommended to set the hop limit to 2 in a container environment.
Resolve the issue
According to AWS documentation, containerized applications running on EKS require the EKS node HttpPutResponseHopLimit in MetadataOptions to be set to 2. To configure this, you can use the following command, replacing <EKS_NODE_INSTANCE_ID> with the instance ID of the specific EKS node you want to retrieve MetadataOptions for.
aws ec2 modify-instance-metadata-options --instance-id <EKS_NODE_INSTANCE_ID> --http-endpoint enabled --http-put-response-hop-limit 1
In many cases, EKS nodes are part of AWS auto scaling groups, making manual modification of instance metadata difficult. To configure Instance Metadata Service (IMDS) for an auto scaling group, you need to modify its associated launch configurations.
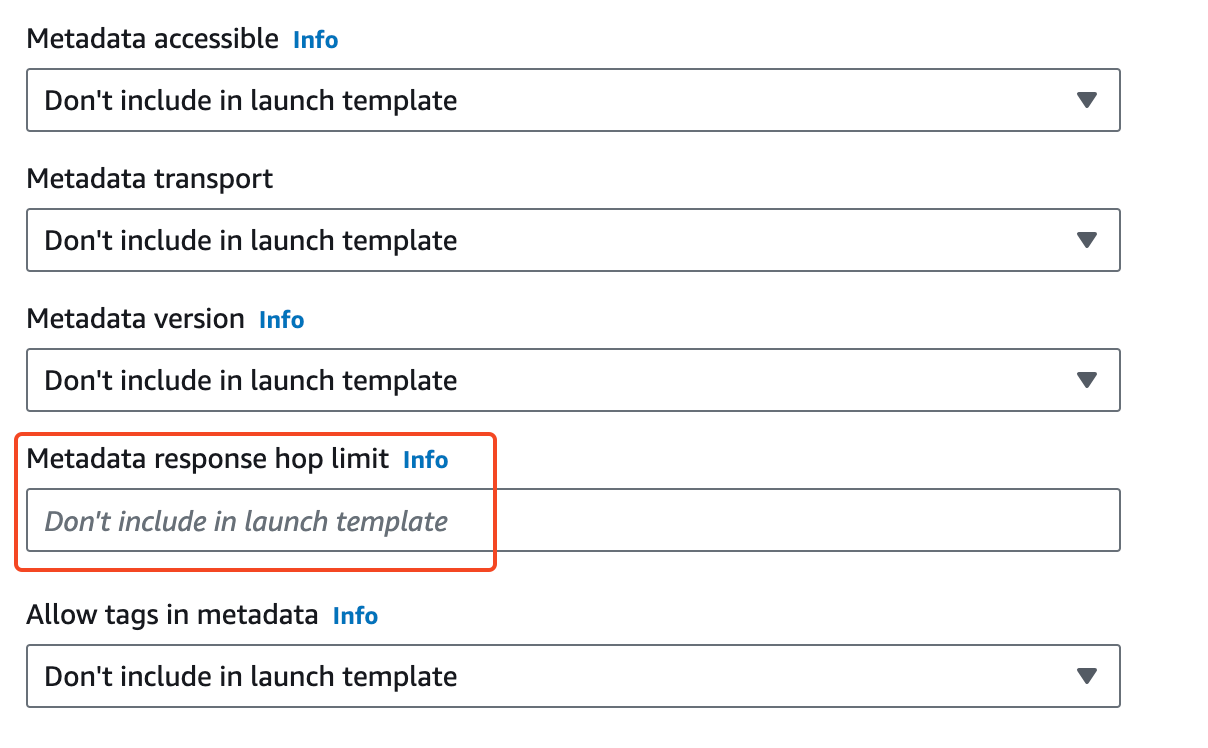
To set the HttpPutResponseHopLimit for all instances associated with the launch configuration, go to the Additional configuration section under Advanced details of the template. Set the Metadata response hop limit to 2. If no value is specified, the default is set to 1.
When using Terraform to provision your infrastructure, you can utilize the aws_launch_template resource to modify instance metadata in the following manner.
resource "aws_launch_template" "foo" {
name = "foo"
metadata_options {
http_endpoint = "enabled"
http_tokens = "optional"
instance_metadata_tags = "disabled"
http_put_response_hop_limit = 2
}
}
After implementing the HttpPutResponseHopLimit modifications, we conducted the same tests as in the investigation phase. The results of both the EKS node and debug pod uploads were nearly identical.
# AWS CLI upload results from the EKS node where the debug pod is running
real 0m1.310s
user 0m0.912s
sys 0m0.078s
# AWS CLI upload results from the debug pod
real 0m1.298s
user 0m0.931s
sys 0m0.082s
Conclusion
In conclusion, our investigation into the significantly slow S3 file uploads from applications running on AWS EKS clusters revealed that the Instance Metadata Service (IMDS) was the root cause of the issue. By comparing upload times from EKS nodes and pods, we identified a delay in establishing the connection to the IMDS endpoint from within the pods. This delay was not present when uploading directly from the EKS nodes.
To resolve this issue, it is necessary to set the HttpPutResponseHopLimit in the MetadataOptions to 2 for EKS nodes. This can be achieved by modifying the associated launch configurations for auto scaling groups or using the aws_launch_template resource in Terraform.
By setting up the HttpPutResponseHopLimit to 2, we can eliminate the latency and significantly improve the speed of file uploads to S3 from AWS EKS pods. This resolution will enhance the overall performance and efficiency of our applications on the EKS cluster.